


How OpenAI’s Bot Overwhelmed a Small Company’s Website ‘Like a DDoS Attack’
-
Amelia Cross

- January 10, 2025
- No Comments

How OpenAI’s Bot Took Down a Small Company’s Website ‘Like a DDoS Attack’
On Saturday, Triplegangers CEO Oleksandr Tomchuk faced an alarming issue: his company’s e-commerce website was down, resembling the effects of a distributed denial-of-service (DDoS) attack. The true culprit, however, turned out to be OpenAI’s bot, which relentlessly attempted to scrape the site’s vast database.
“We have over 65,000 products, each with a dedicated page and at least three photos,” Tomchuk told TechCrunch. OpenAI’s bot sent “tens of thousands” of server requests, attempting to download hundreds of thousands of photos and detailed product descriptions.
Using approximately 600 IPs, the bot’s activity overwhelmed Triplegangers’ servers. “Their crawlers were crushing our site,” Tomchuk said. “It was basically a DDoS attack.”
Triplegangers, a seven-person team based in Ukraine with a U.S. license in Tampa, Florida, has spent over a decade building the web’s largest database of “human digital doubles” — 3D image files scanned from real human models. These files, along with photos of hands, hair, skin, and full bodies, are sold to 3D artists, video game developers, and others needing realistic human characteristics.
Although the company’s terms of service prohibit bots from taking images without permission, that wasn’t enough. Websites must also use a properly configured robots.txt file with tags specifically instructing OpenAI’s bots, such as GPTBot, to avoid crawling the site. OpenAI states it honors these files but warns it may take up to 24 hours to recognize updates. Without this setup, bots can scrape freely, as Triplegangers painfully discovered.
In addition to the downtime, Tomchuk anticipates a significantly higher AWS bill due to the intense server activity. While robots.txt offers some protection, compliance by AI companies remains voluntary, as evidenced by previous allegations against startups like Perplexity for bypassing these directives.
Tomchuk’s experience highlights the challenges smaller businesses face in defending their resources against powerful AI scrapers in a rapidly evolving digital landscape.
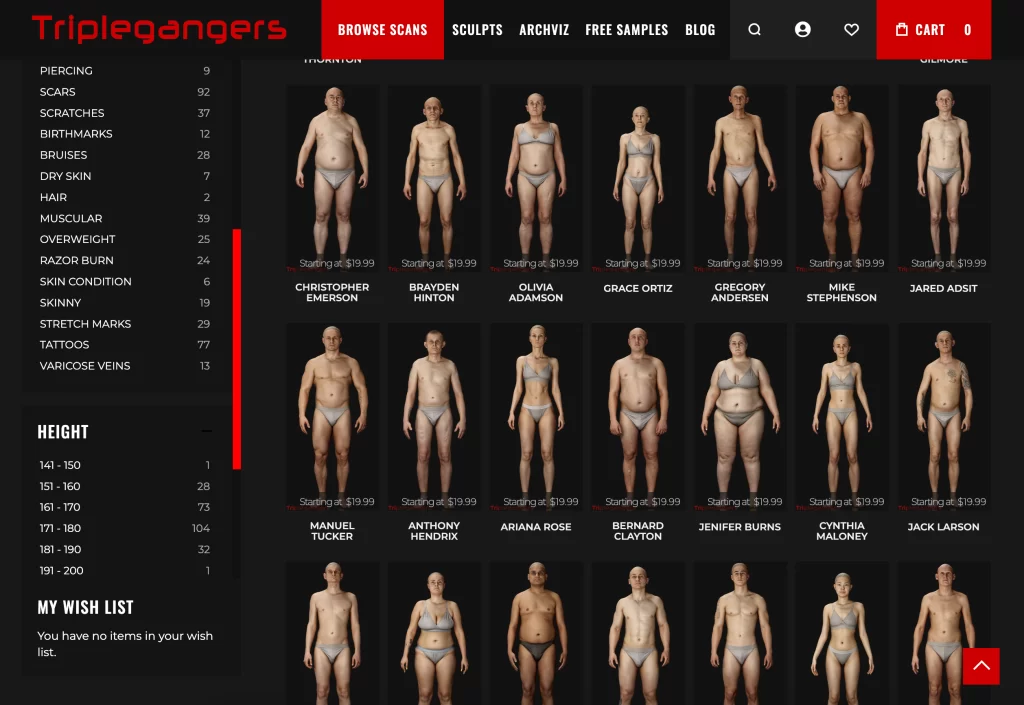
Each of these is a product, with a product page that includes multiple more photos. Used by permission.Image Credits:Triplegangers(opens in a new window)
By Wednesday, after days of disruption caused by OpenAI’s bot, Triplegangers had implemented a properly configured robots.txt file and set up Cloudflare to block GPTBot and other crawlers like Barkrowler (an SEO bot) and Bytespider (TikTok’s bot). By Thursday, the site had stabilized, but CEO Oleksandr Tomchuk still faces a major issue: he has no way of knowing exactly what OpenAI’s bot managed to scrape or how to have the data removed.
“There’s no way to contact OpenAI,” Tomchuk said. OpenAI didn’t respond to TechCrunch’s request for comment, and the company has yet to deliver on its promise of an opt-out tool for data scraping.
This lack of clarity is particularly problematic for Triplegangers, whose business revolves around scanning real people to create 3D models. “We’re in a business where rights are a serious issue because we scan actual people,” Tomchuk explained. Under laws like Europe’s GDPR, “they cannot just take a photo of anyone on the web and use it.”
Triplegangers’ website is a treasure trove for AI crawlers, with photos meticulously tagged for ethnicity, age, body type, tattoos, scars, and more—essential data for training AI models. This level of detail makes the site a prime target for data-hungry companies.
Ironically, the sheer aggressiveness of OpenAI’s bot is what tipped off Triplegangers to its vulnerability. “If they had scraped more gently, we never would have known,” Tomchuk said.
He criticized the opt-out system, which requires businesses to proactively configure their robots.txt files to block bots like GPTBot. “It’s scary because there seems to be a loophole these companies are exploiting,” Tomchuk added, noting that the burden unfairly falls on small businesses to navigate the technical steps required to protect their data.
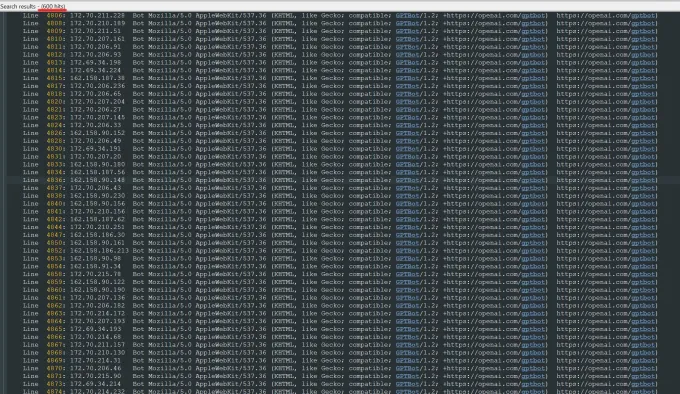
Triplegangers’ server logs showed how ruthelessly an OpenAI bot was accessing the site, from hundreds of IP addresses. Used by permission.
Tomchuk wants small online businesses to understand that the only way to detect if an AI bot is scraping copyrighted content is through active monitoring. He’s not alone in facing such challenges—other website owners have shared with Business Insider how OpenAI bots crashed their sites and inflated their AWS bills.
The issue escalated significantly in 2024. Research from digital advertising firm DoubleVerify revealed that AI crawlers and scrapers were responsible for an 86% increase in “general invalid traffic” that year—traffic originating from non-human sources.
“Most sites have no idea they’ve been scraped by these bots,” warns Tomchuk. To safeguard his site, he now monitors log activity daily to identify suspicious behavior.
“It’s like a mafia shakedown,” he adds. “These AI bots will take whatever they want unless you have the protection to stop them.”







